Ubooquity 1.7.6, bug fixes
29 march 2015 Release
Ubooquity 1.7.6 is available.
Just minor bug fixes.
Fixed bugs
- Fixed option to bypass single root folder
- Apply "java.awt.headless" system flag when using headless option
Ubooquity 1.7.5, minor release
21 march 2015 Release
Ubooquity 1.7.5 is available.
This is a minor release: a few bug fixes and a few very specific features.
Fixed bugs
- Problem with special characters (e.g. accents) in user names with iOS
- Incorrect comics file name when downloading (happened when comics contained metadata, the downloaded file name was the title instead of being the original file name)
-
Incorrect sorting of comics titles containing accents
This bug is fixed only on new databases. This means that if you want to have this bug fixed when updating Ubooquity, you will have to manually delete the file "ubooquity-4.h2.db" in your working directory (after having stopped Ubooquity of course). Since this file contains the scanned comics and ebooks data, this operation will trigger a full rescan of your collection.
New features
- Limited* support for WebP images in comics
- Limited* support of DJVU files
- New advanced option to exclude folders from scan using regular expressions
- New advanced option to bypass root folder page when there is only one root folder
* Limited by the platform Ubooquity will run on. Both feature were succesfuly tested on Windows, but they don't work on Raspberry Pi (Linux). So they might or might not work depending on your setup. These limitations come from the libraries I use, nothing I can do about it.
Technical stuff
- Added an OPDS tag for "current folder content" (should be used by Chunky reader in the future)
- Allowed use of fonts and SVG files in themes, for better customization possibilities
A word of warning for Java 6 users. This the last version supporting Java 6. Next version will require Java 7 to run. (Java 6 has been obsolete for many years anyway)
Ubooquity 1.7.0, with OPDS and comics metadata
14 december 2014 Release
Ubooquity 1.7.0 is available.
 This upgrade will trigger a complete rescan of your of comics and ebooks files. You will not lose your settings, but depending on the size of your collection, it could take time.
This upgrade will trigger a complete rescan of your of comics and ebooks files. You will not lose your settings, but depending on the size of your collection, it could take time.
If you use the "Modern" theme, you will have to download the new version of this theme on the themes page.
New features
- Comics Metadata : Ubooquity now reads and displays comics metadata in the ComicRack format. You can write such metadata in your comics with applications like ComicRack (obviously) or ComicTagger.
- Better PDF support : Ubooquity now embeds two new libraries which will improve PDF support, especially for documents containing JPG2000 images or using cryptography features (not fully encrypted PDF though). They will no longer generate errors when scanned and their cover will be displayed correctly.
- OPDS feeds : You can activate OPDS feeds in the "advanced" option of Ubooquity. Your feeds will be available at the following addresses (port and IP are just examples):
http://10.0.0.1:2202/opds-comics
http://10.0.0.1:2202/opds-books
These feeds support authentication through HTTP Basic Authentication (same credentials as the ones you already use). This authentication method is not as secure as the one already used by Ubooquity, so be carefull if you use OPDS feeds on an open network without activating the SSL/HTTPS feature.
I have done some tests with a few ebooks/comics readers with OPDS support. Unfortunately the OPDS specification is not followed at 100% by all the applications. Here are the results of my tests:
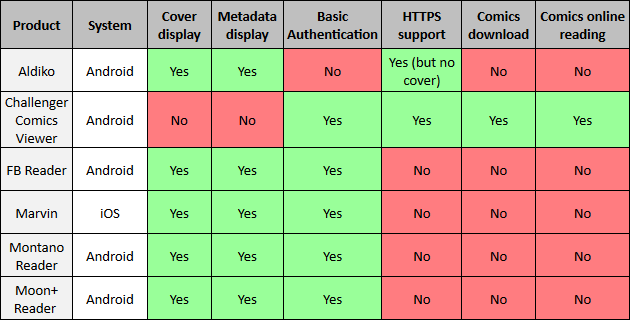
Note that the the "Comics online reading" column corresponds to a feature not supported by the original OPDS standard but is an extension developped for Ubooquity and Challenger Comics Viewer. More details here.
Miscellaneous
- Added an option to automatically minimize Ubooquity interface at startup.
- Added an option to hide empty folders.
- Improved ebooks metadata display (publication date, language, file format).
- Trailing slashes and backslashes are now automatically removed when entering shared folder paths in the web administration page.
- Fixed a rare bug which added a pink overlay on some comics images.
- Fixed a bug on folder images: Ubooquity now always uses the first image found in the directory or its subdirectories.
The improved comics online reader development is still in progress.
Ubooquity 1.6.0, with SSL support (HTTPS)
26 october 2014 Release
Ubooquity 1.6.0 is available.
[UPDATE] If you use the "Modern" theme, you will have to download the new version of this theme on the themes page.
New features
- SSL support : You can now access your files in a more secure way by using the HTTPS protocol instead of HTTP. To do that you will need to get a SSL certificate (either by buying one or generating a self-signed one), generate a Java keystore and configure Ubooquity to use it.
- Reverse proxy : If you want to use reverse proxy, you can now choose the prefix which will be added at the beginning of every URL served by Ubooquity.
- "New comics/books" links : two new links on the home page which will take you to a page containing the latest comics and books added to your collection.
Miscellaneous
- Added an option to disable files auto scan at startup (if you want your files scanned only when you press the "scan" button).
- Failed logon attempts for the webadmin page are now displayed on a single line so that they are easier to parse with fail2ban.
- Log files rotate when they reach 1 MB instead of 5 MB.
- Removed session limitation restricting a user to a single active session (you were automatically logged out of a device when logging into another). You can now have several sessions on different devices at the same time.
- Removed port range restriction (ports under 1024 are now authorized).
- Fixed advanced preferences page in webadmin.
- Fixed several bugs related to user rights management.
- Fixed a bug preventing the comic pages displayed in the online reader from being wider than 1200 pixels.
- Fixed online reader keyboard shortcuts in Chrome.
- Fixed a bug which was degrading perfomances of the online reader when a scan was in progress.
No OPDS support yet, and the online reader has not been improved much either. But work is in progress and these features/improvements will probably be delivered in the 1.7.0 version.
A forum to exchange ideas and questions around Ubooquity
02 september 2014 General
The ubooquity website now has a dedicated forum, hosted on UserEcho.
This forum is meant to gather your feedback (questions, ideas, bugs...) in a single place so that discussions between users can take place more easily than in the comments section of the news. It also has a few interesting features:
- A voting system that will help me to know among the feature I'm asked to implement the ones that are the most popular.
- A status label ("planned", "started", "declined") displayed on feature requests that will give you a better visibility over the future of the application.
- An integrated search engine to easily find topics when looking for informations.
Private messages can also be directly sent to me through the forum. I will keep the contact page online for now, but they are redundant.
The only drawback: you will have to sign in to the forum before being able to post or send a message. But you can do that using a lot of different account provider (Google, Yahoo, Microsoft, OpenID...) or by directly creating a UserEcho account, so it should not be a big problem.
Go to the forum by clicking the "Forum" link in the top menu or the "Feedback" label on the right side of your screen.
